معرفی Apache hadoop #
کتابخانه نرم افزار Apache Hadoopکه منبع باز (open source) نیز می باشد، چارچوبی (framework) است که با استفاده از مدل های برنامه نویسی ساده، امکان پردازش توزیع شده (distributed processing) مجموعه داده های بزرگ را از طریق خوشه های کامپیوتر (Computer Clusters) فراهم می کند. طراحی آن به گونه ای است که از سرورهای منفرد به هزاران ماشین افزایش مقیاس (scale up) پیدا می کند و هر ماشین نیز به طور محلی، امکان محاسبات و ذخیره سازی دارد. به منظور دسترسی بالا، شناسایی و رسیدگی به خرابیها بهجای تکیه بر سختافزار، در لایه برنامه (Application layer) طراحی شده است، بنابراین در بالای مجموعهای از کامپیوترها که هر یک ممکن است مستعد خرابی باشند، یک سرویس بسیار در دسترس را فراهم می کند.

در واقع Apache Hadoop برای رفع چالش های ابر محاسبات (Super Computing) طراحی شده است. چالشهایی نظیر اینکه برای نیازهای محاسبات موازی در ابر محاسبات، یک سیستم عامل همه منظوره مانند چارچوب وجود نداشت یا شرکتهایی که برای محاسبات باید ابر کامپیوتر تهیه میکردند، برای تهیه و پشتیبانی سختافزاری منحصر به فروشندگان خاص می شدند، ضمن اینکه هزینه اولیه بالایی برای سخت افزار باید متحمل میشدند. همچنین نرم افزارهای مرتبط با آن محاسبات نیز باید به صورت شخصی سازی شده برای هر سازمان توسعه داده می شد که هزینه توسعه و پشتیبانی بالایی داشت. اما HADOOP با رفع همه این چالشها، سازمانهای ذینفع را نجات داد.
در انتخاب سیستم عامل برای نصب Apache hadoop، ترجیحا لینوکس (توزیع اوبونتو (Ubuntu) یا سایر توزیعهای لینوکس) را انتخاب کنید زیرا به دلیل ثبات، امنیت و انعطاف پذیری به طور کلی بهترین سیستم عامل برای اجرای Hadoop در نظر گرفته می شود. علاوه بر این، لینوکس منبع باز است و دارای یک جامعه بزرگ از توسعه دهندگان است که در توسعه مداوم Hadoop مشارکت دارند.
معماری Apache hadoop #
معماری Apache hadoop به صورت خادم/مخدوم یا master/slave است. معماری در ویرایشهای مختلف hadoop که در زمان نگارش این متن، ویرایش سوم آن منتشر شده، تغییراتی داشته است. که برای درک بهتر این تغییرات ابتدا معماری ویرایش یک آن را توضیح می دهیم:
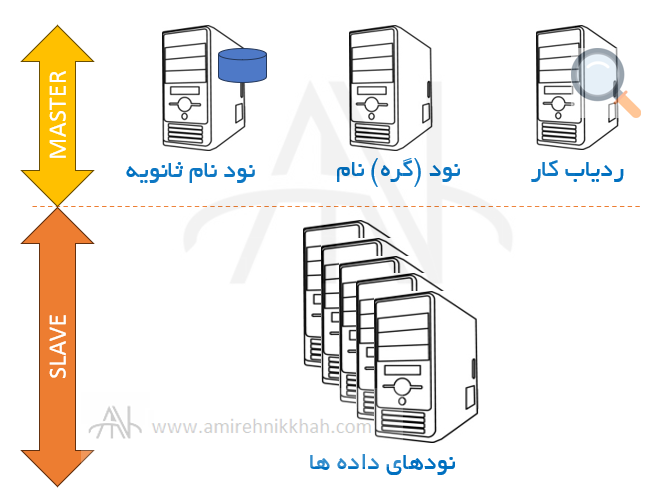
اجزای Master #
- گره نام (Name node): مدیر فایل سیستم مرکزی.
- گره نام یا گره نام فعال، فراداده (Meta data) هر بلوک داده و کپی های آن را ردیابی می کند. فراداده شامل نام فایل، مجوز، شناسه، مکان و تعداد کپیها از فایل میشود. تمام اطلاعات را در fsimage که یک تصویر فضای نام (Namespace) ذخیره شده در حافظه محلی فایل سیستم است، نگه می دارد. علاوه بر این، لاگ های تراکنشها (transaction logs) را در EditLogs نگهداری کرده و تمام تغییرات ایجاد شده در سیستم را ثبت می کند.
- گره نام ثانویه (Secondary name node): پشتیبان گیر از اطلاعات گره نام است و در حالت آماده به کار (standby) نمی باشد.
- ردیاب کار (Job tracker): زمانبندی کننده کار به صورت متمرکز.
اجزای Client #
گره های مخدوم (slaves) و برنامه های پس زمینه (deamons)/سرویسهای نرم افزاری (software services) در این بخش قرار دارند:
- گره داده ها (data node): ماشینی که فایلها در آن ذخیره و پردازش میشوند. هر گره slave هر ۳ ثانیه یک بار، سیگنال به گره نام
می فرستد تا اعلام فعال بودن کند. - ردیاب وظیفه (Task Tracker): یک سرویس نرم افزاری است که وضعیت ردیاب کار را پایش می کند.
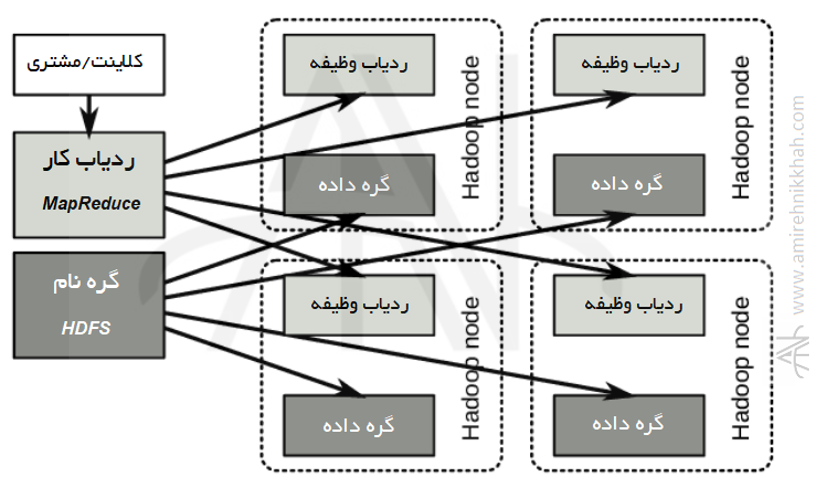
ماژول های مهم Apache hadoop #
ماژول های مهم apache hadoop عبارتند از:
- Hadoop Distributed File System (HDFS): یک فایل سیستم توزیع شده با قابلیت دسترسی با توان عملیاتی بالا به داده های برنامه .
- Hadoop YARN: چارچوبی برای زمانبندی کار و مدیریت منابع خوشهای.
- Hadoop MapReduce: سیستمی مبتنی بر YARN برای پردازش موازی مجموعه داده های بزرگ.
Hadoop Distributed File System (HDFS) #
HDFS، یک فایل سیستم توزیع شده است که دسترسی با توان عملیاتی بالا (high-throughput access) به داده های برنامه را فراهم می کند. به بیان دیگر HDFS لایه ذخیره سازی داده در Apache Hadoop است. داده ها در گره های داده (Data Nodes) ذخیره می شوند. برای جلوگیری از دست رفتن داده، در ویرایش های اول و دوم Apache hadoop ذخیره سازی داده در چند نود بر اساس مقدار عامل تکرار (Replication Factor) که پیش فرض آن عدد ۳ است، انجام می شود. در ضمن، شما می توانید هنگام کپی فایل، مقدار عامل تکرار را مشخص کنید. در مثال زیر نحوه عملکرد HDFS در ذخیره سازی فایل در ویراش اول و دوم Apache hadoop بیان شده است:
مثال ذخیره سازی داده در ویرایش اول و دوم Apache hadoopبر اساس عامل تکرار #
فرض کنید فایلی به نام sample.txt به حجم ۲۰۰ مگابایت را می خواهیم ذخیره کنیم. ماشینهای درگیر فعال برای این ذخیره سازی عبارتند از: ماشین کلاینت/مشتری، ماشین گره نام فعال وگره های داده.
با توجه به اندازه تقسیم فایل (Split size) که می تواند ۶۴، ۱۲۸ و… مگابایت باشد (قابل تغییر است)، فایل به بلوکهایی تقسیم می شود. در این مثال اگر اندازه تقسیم فایل را ۶۴ مگابایت درنظر بگیریم، sample.txt به ۳ بلوک ۶۴ مگابایتی و ۱ بلوک ۸ مگابایتی و مجموعه ۴ بلوک تقسیم می شود. جزییات قرار گیری این بلوکها روی گره های نود را گره نام تعیین می کند و بر اساس این جزییات، بلوکها توسط کلاینت بر روی گره های نود ذخیره می شوند.
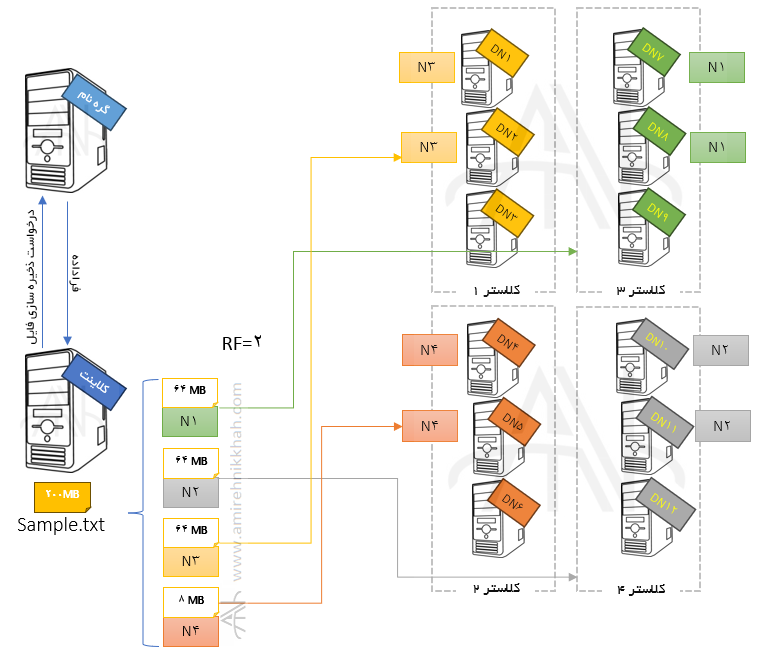
در مثال بالا اگر گره داده ۱۱ (DN11) خراب (fail) شود، در این صورت بلافاصله یک نسخه از N2 روی نزدیکترین گره داده یعنی DN12 می نشیند د و اگر DN11 پس از مدتی دوباره فعال شود، HDFS یکی از سه نسخه N2 را حذف می کند به این ترتیب در هر حالت، عامل تکرار یعنی RF=2 برای همه بلوکهای داده رعایت می شود.
همانطور که در مثال بالا مشاهده می کنید بر اساس مقدار عامل تکرار (Replication factor) که به طور پیش فرض ۳ است، مقدار زیادی از فضای دیسک برای نگهداری تکرارها استفاده می شود. در ویرایش سوم به منظور رفع این نقص، از مفهوم بیتهای توازن (Parity bits) استفاده شده و به این ترتیب فضای ذخیره سازی تا ۵۰% کاهش می یابد. در ادامه، با مثالی نحوه ذخیره سازی داده بر اساس بیتهای توازن را نشان می دهیم:
مثال ذخیره سازی داده در ویرایش سوم Apache hadoop بر اساس بیتهای توازن #
داده موردنظر برای ذخیره سازی را به فرمت باینری به صورت ۱۰۱۱۰۱۰۰۱۱۰۱ در نظر بگیرید. فرض کنید دیتا به سه بلوک ۱۲۸ مگابایتی N1, N2 و N3 تقسیم می شود. در شکل زیر نحوه استفاده از بیت توازن برای ذخیره و بازیابی اطلاعات نشان داده است:
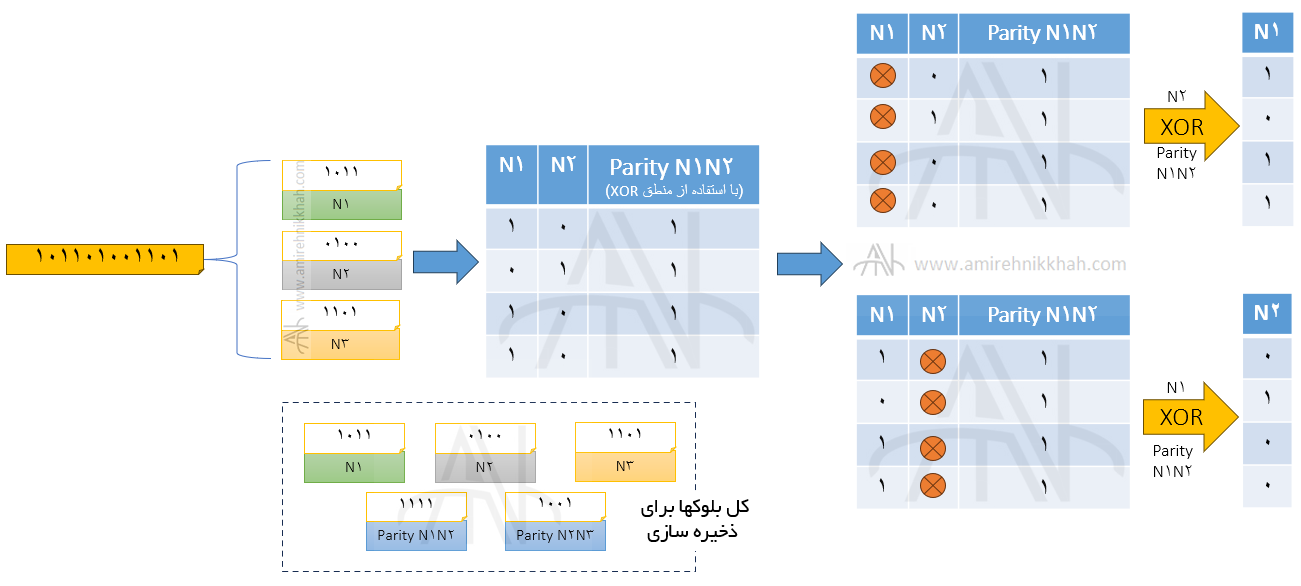
همانطور که در شکل بالا مشاهده می شود، بیتهای توازن بر اساس منطق XOR از هر دو بلوک ساخته می شوند و درصورتی که هر یک از بلوکهای N1 یا N2 از بین روند، با استفاده از Parity N1N2 و بلوک سالم، دیگری ساخته خواهد شد. در ضمن در مجموع ۵ بلوک داده ذخیره خواهد شد، این در حالیست که در ویرایش دوم با RF=3، تعداد ۹= 3*۳ بلوک باید ذخیره می شد. یعنی با درنظر گرفتن این مثال، در ویرایش ۳ به نسبت ویرایش ۲ Apache hadoop، بیش از ۴۰% صرفه جویی در فضای ذخیره سازی رخ داده است.
متوازن کننده داخلی گره داده در Apache Hadoop V3 #
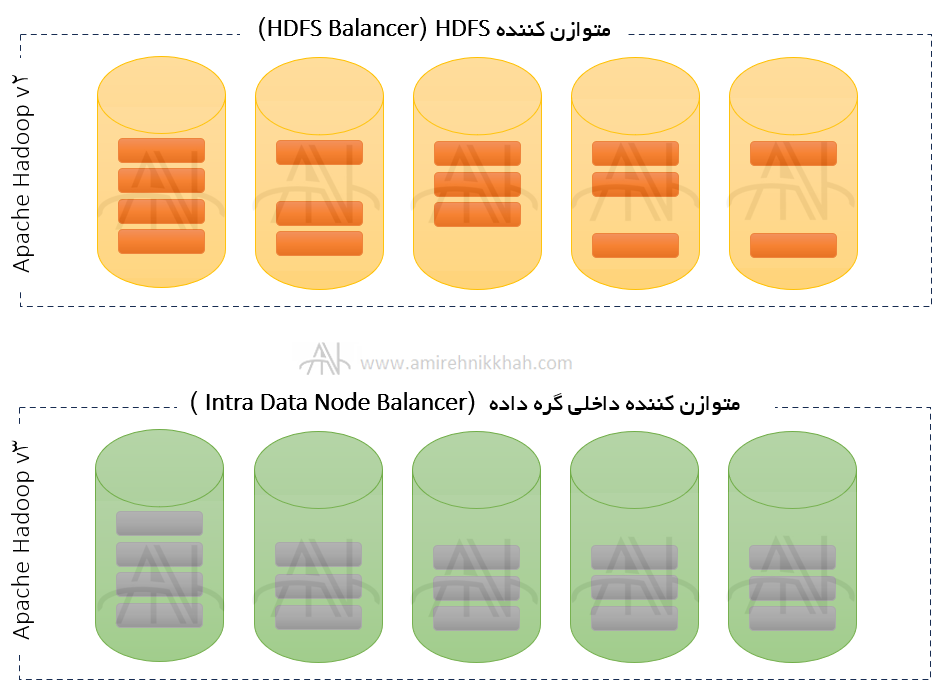
یک گره داده دارای هارد دیسک های متعددی است. توزیع ناهنجار داده در هارد دیسک های یک گره داده به دلیل حذف داده ها و افزودن داده های جدید به HDFS ایجاد می شود. متوازن کننده HDFS در ویرایش دوم Apache Hadoop توازن را در گره های داده ایجاد می کند ولی تضمین نمی کند که داده ها در همه هارد دیسک های یک گره به طور یکنواخت توزیع شوند. در ویرایش سوم Apache Hadoop، متوازن کننده داخلی گره یا Intra Data Node Balancer اضافه شده که این مشکل را رفع می کند و توازن توزیع داده در همه هارد دیسکهای یک گره داده را تضمین می کند.
Hadoop YARN #
Hadoop YARN که از ویرایش دوم به جای Job Tracker اضافه شده، چارچوبی برای زمانبندی کار (job scheduling) و مدیریت منابع خوشهای (cluster resource management)است.
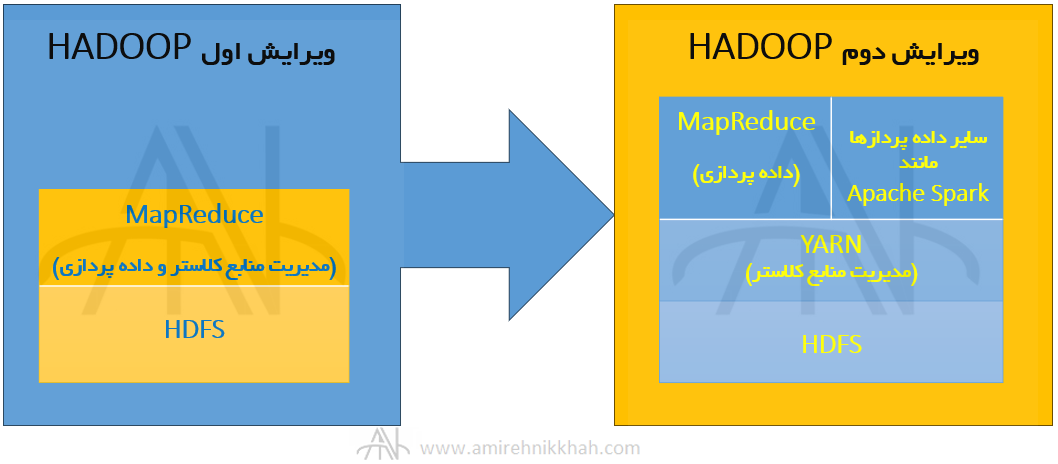
Hadoop YARN که در ویرایش دوم Apache hadoop، جایگزین ردیاب کار در ویرایش یک (Job tracker) شده، وظیفه یک زمانبندی کننده و مدیر متمرکز منابع در کلاستر است. در ویرایش یک، مدیریت منابع کلاستر به عهده MapReduce بود. ولی در ویرایش دو، این مسئولیت بر عهده YARN است، به این ترتیب در ویرایش دو، MapReduce تنها فعالیت داده پردازی (data processing) دارد. به این ترتیب، این امکان فراهم می آید که بتوان از سایر داده پردازها مانند اسپارک (Spark) نیز استفاده کرد.
Hadoop MapReduce #
یک سیستم مبتنی بر YARN برای پردازش موازی (parallel processing) مجموعه داده های بزرگ است زیرا MapReduce چندین مزیت برای پردازش داده های بزرگ یا کلان داده ها ارائه می دهد که از آن جمله می توان به مقیاس پذیری (scalability)، تحمل خطا (fault tolerance)، انعطاف پذیری (flexibility)، محلی بودن داده ها (data locality)، سادگی (simplicity)، مقرون به صرفه بودن (cost-effectiveness)، و ادغام با سایر فناوری ها اشاره کرد.
MapReduce چگونه کار می کند؟ #
MapReduce چگونه سرعت پردازش را افزایش می دهد؟ #
در حالتیکه بخواهید مثلا روی پردازش متن کار کنید و با کلان داده طرف باشید، زمان لازم برای پردازش فایلها بسیار بالا خواهد رفت. فرض کنید بجای ۱۰ خط برای پردازش، فایل ۷۰۰ مگابایتی داشته باشید. در این حالت باید از ابزارهایی مانند MapReduce استفاده کنیم. اما چگونه MapReduce سرعت پردازش را افزایش می دهد؟
در این حالت در چارچوب Hadoop، فایل به بلوکهای مثلا ۶۴ بایتی می شکند و هر بلوک جداگانه ولی به طور همزمان با سایر بلوکها پردازش می شود. به این ترتیب که به یک از بلوکها یک Record-reader ویک Mapper جداگانه تخصیص داده می شود. در انتها خروجی همه Mapper ها به Reducer داده می شود (به طور پیش فرض یک Reducer وجود دارد ولی با توجه به سطح بهینه سازی می توان تعداد بیشتری هم استفاده کرد) و پردازش نهایی انجام می شود.
موارد استفاده MapReduce #
برخی از موارد استفاده از MapReduce عبارتند از:
- – بیشتر برای جستجوی کلمات کلیدی در حجم انبوه داده استفاده می شود.
- – گوگل از آن برای شمارش کلمات، تبلیغات، رتبه صفحه، فهرستبندی دادهها برای جستجوی گوگل، خوشهبندی مطالب برای Google News استفاده میکند.
- – یاهو با آن، «نقشه وب» را برای تقویت جستجو تشکیل داده و همچنین برای تشخیص هرزنامه استفاده می کند.
- – الگوریتم های ساده مانند grep، فهرست بندی متن (text indexing)، نمایه سازی معکوس (reverse indexing).
- – در حوزه داده کاوی کاربرد دارد.
- – فیس بوک از آن برای داده کاوی، بهینه سازی تبلیغات، تشخیص هرزنامه استفاده می کند.
- – خدمات مالی از آن برای تجزیه و تحلیل استفاده می کنند.
- – در ستاره شناسی برای تجزیه و تحلیل گاوسی برای مکان یابی اجرام فرازمینی به کار می رود.
- -اکثر وظایف تجزیه و تحلیل که به صورت غیرتعاملی دسته ای هستند با آن انجام می شوند.
پیکربندی Apache hadoop #
Apache Hadoop از ۳ حالت پیکربندی پشتیبانی می کند:
- مستقل (Standalone mode): همه سرویسها به صورت محلی بر روی یک دستگاه واحد در یک JVM اجرا میشوند (به ندرت استفاده میشود).
- شبه توزیع شده (Pseudo distributed mode): همه سرویس ها بر روی یک دستگاه اما روی یک JVM متفاوت اجرا می شوند. با هدف توسعه و آزمایش استفاده می شود.
- کاملاً توزیع شده (Fully distributed mode): هر سرویس بر روی یک سخت افزار مجزا (یک سرور اختصاصی) اجرا می شود. برای ستاپ تولید و بهره برداری استفاده می شود.
منظور از سرویس، Data node, Name Node , … است که از اجزای معماری Apache hadoop هستند.




