انواع الگوریتمهای یادگیری ماشین شامل یادگیری تخت نظارت، یادگیری بدون نظارت، یادگیری نظارت شده و یادگیری تقویتی هستند که در ادامه به آن می پردازیم
یادگیری تحت نظارت #
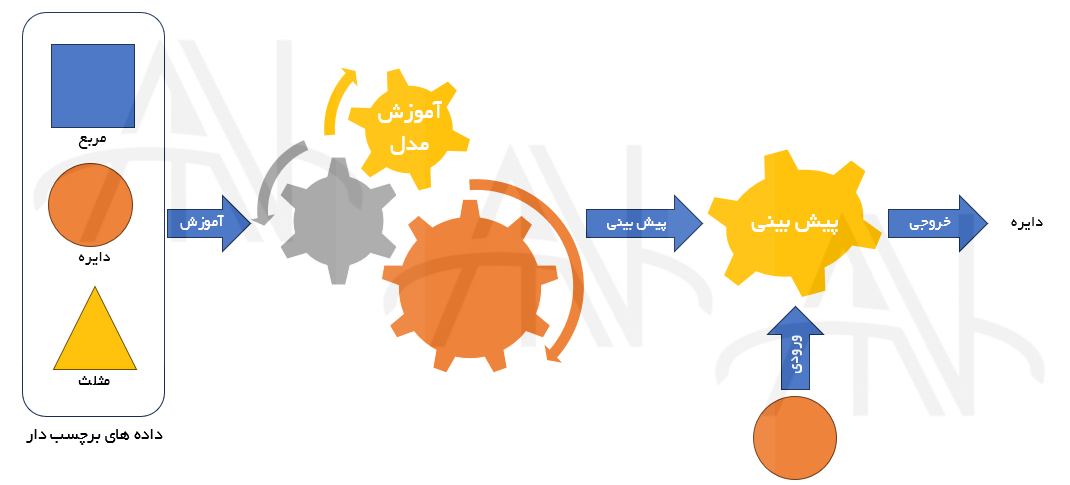
یادگیری تحت نظارت یا Supervised Learning، دسته ای از الگوریتم های یادگیری ماشین هستند که از نمونه داده شناخته شده (که مجموعه داده های آموزشی نیز نامیده می شود) و خروجی های مرتبط (که به برچسب یا پاسخ نیز معروفند) با هر نمونه داده، در فرآیند یادگیری مدل استفاده می کنند.
هدف اصلی، یادگیری نگاشت یا ارتباطی بین نمونه داده های ورودی x با خروجی های متناظر آن ها y بر مبنای نمونه داده های آموزشی ست. این دانش آموخته شده بعدا در آینده برای پیش بینی خروجی y’ برای هر نمونه داده جدید x’ که قبلا در فرآیند آموزش مدل؛ دیده نشده و ناشناس است، به کار می رود. اصطلاح یادگیری تحت نظارت برای این روش ها به این دلیل به کار رفته که این مدل ها از نمونه های داده ای یاد می گیرند که برچسب ها/پاسخ های خروجی موردانتظار آنها قبل از فرآیند آموزش شناخته شده هستند.
با یادگیری تحت نظارت، رابطه بین ورودی ها و خروجی های متناظر آن ها از روی داده های آموزشی، مدل سازی می شود تا بتوان پاسخ های خروجی برای داده های ورودی جدید را بر اساس دانشی که قبلا درباره روابط و نگاشت بین ورودی ها و خروجی های هدف به دست آمده، پیش بینی کرد. دقیقا به همین دلیل از روش های یادگیری تحت نظارت به طور گسترده در تجزیه و تحلیل پیش بینی استفاده می شود.
یادگیری بدون نظارت #
یادگیری تحت نظارت زمانی عالی است که یک حجم بزرگ از نمونه های برچسب دار در دسترس باشد. وقتی بتوان هزاران نمونه از آنچه که یک ماشین باید یاد بگیرد را فراهم کرد، می توان یادگیری ماشین را کنترل کرد. اما این کار همیشه امکان پذیر نیست. ایجاد چنین مجموعه داده ای می تواند مدت ها طول بکشد و کارهای دستی زیادی نیاز دارد. گاهی اوقات هم مسائل با آن جور نمی شوند. در این شرایط است که به سراغ یادگیری بدون نظارت می رویم.
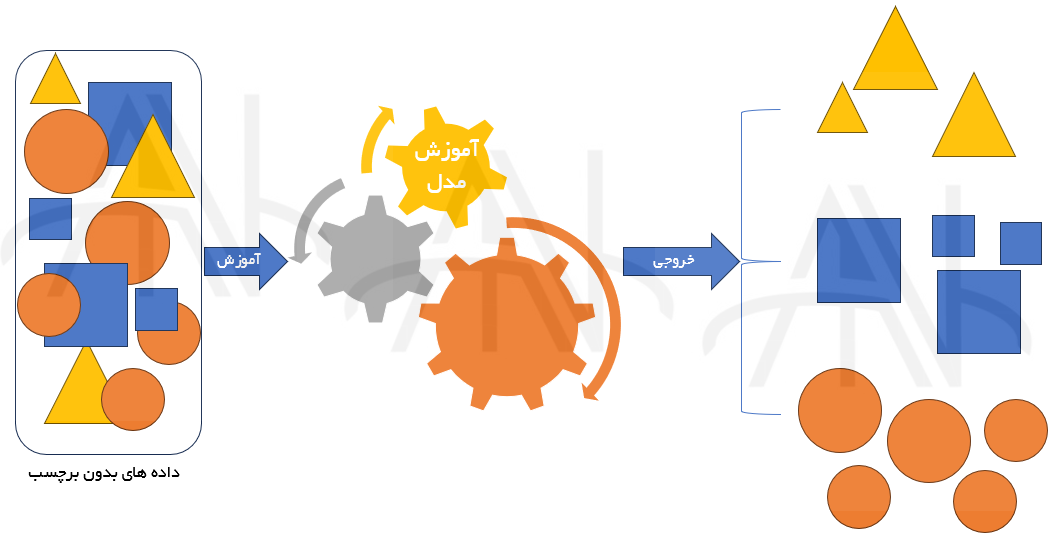
در یادگیری بدون نظارت، Unsupervised learning مجموعه داده های ورودی، بدون قالب های برچسب دار هستند. این روش ها بدون نظارت نامیده می شوند، زیرا مدل یا الگوریتم تلاش می کند ساختارها، الگوها و روابط ذاتی را از داده های مفروض بدون هیچ گونه کمک و نظارتی (مانند حاشیه نویسی و برچسب گذاری خروجی ها) یاد بگیرد.
یادگیری بدون نظارت به جای پیش بینی برخی نتایج بر اساس داده های آموزشی، تلاش می کند تا بینش یا اطلاعات معنادار از داده ها استخراج کند. در نتایج یادگیری بدون نظارت عدم اطمینان بیشتری وجود دارد، اما می توان از این مدل ها اطلاعات زیادی کسب کرد که قبلا فقط با نگاه کردن به داده های خام قابل دسترس نبود.
یادگیری بدون نظارت اغلب می تواند یکی از وظایف مربوط به ایجاد یک سیستم ابر هوش مصنوعی باشد. در مورد استفاده از فقط یک تکنیک خاص، هیچ قانون سخت و سریعی وجود ندارد و همیشه می توان برای حل مسئله چندین روش را با هم تلفیق کرد. خوشه بندی (Clustering)، کاهش بُعد (Dimensionality Reduction)، کشف ناهنجاری (Anomaly Detection)، قاعده کاوی (Rule Mining) از روش های یادگیری بدون نظارت هستند. این روش ها به ویژه در زمینه هایی مانند هنر دیجیتال (Digital Art) و تشخیص تقلب و کلاه برداری(Fraud Detection) مفید هستند.
یادگیری نیمه نظارت شده #
روش های یادگیری نیمه نظارت شده، Semi-Supervised Learning، معمولا بین روش های یادگیری تحت نظارت و بدون نظارت قرار می گیرند. این روش ها معمولا از داده های آموزشی زیادی استفاده می کنند که بدون برچسب هستند (که بخش یادگیری بدون نظارت را تشکیل می دهند) و مقدار کمی از داده های از قبل برچسب گذاری شده (که بخش یادگیری تحت نظارت را تشکیل می دهند) استفاده می شود. در این حوزه تکنیک های متعددی در قالب روش های مولد (Generative Methods)، روش های مبتنی بر نمودار (Graph Based Methods) و روش های اکتشاف محور(Heuristic Based Methods) وجود دارند.
یک رویکرد ساده این است که یک مدل تحت نظارت بر اساس داده های برچسب دار که محدودند، ایجاد شود و سپس آن مدل بر مقادیر زیادی از داده های بدون برچسب اعمال شود تا نمونه های برچسب دار بیشتری به دست آمده، مدل با آنها آموزش ببیند و فرآیند تکرار شود. رویکرد دیگر، استفاده از الگوریتم های بدون نظارت به منظور خوشه بندی نمونه داده های مشابه، استفاده از اقدامات انسانی در چرخه برای برچسب گذاری این گروه ها و سپس استفاده از ترکیبی از این اطلاعات در آینده است. این روش در بسیاری از سیستم های علامت گذاری تصویر استفاده می شود.
یادگیری تقویتی #
در یادگیری تقویتی، Reinforcement Learning، یک عامل وجود دارد که می خواهیم طی یک دوره زمانی آموزش ببیند تا بتواند با یک محیط خاص تعامل برقرار کرده و عملکردش را در یک دوره زمانی با توجه به نوع عملیات محیط، بهبود دهد. به طور معمول، عامل شروع با مجموعه ای از استراتژی ها یا سیاست ها برای تعامل با محیط شروع می کند. با مشاهده محیط و وضعیت فعلی آن، اقدام خاصی بر اساس یک قاعده یا سیاست انجام می دهد. بر اساس این اقدام، عامل پاداش می گیرد که می تواند از نوع سود یا زیان باشد به شکل جریمه.
اگر لازم باشد، عامل سیاست ها و استراتژی های فعلی خود را به روز می کند و این فرآیند تکرارشونده ادامه می یابد تا زمانی که به اندازه کافی در مورد محیط اش یاد بگیرد و پاداش دلخواهش را دریافت کند. گام های اصلی روش یادگیری تقویتی به شرح زیر است:
۱- تهیه عامل با مجموعه سیاست ها و استراتژی های اولیه
۲- مشاهده محیط و وضعیت فعلی
۳- انتخاب سیاست بهینه و انجام اقدام
۴- (دریافت پاداش متقابل (یا جریمه
۵- در صورت لزوم، به روزرسانی سیاست ها
۶- تکرار مراحل ۲ تا ۵ تا زمانی که عامل بهینه ترین سیاست ها را یاد بگیرد
یکی از مسائل واقعی، تلاش برای آموزش یک ربات یا ماشینی ست که بتواند شطرنج بازی کند. در این حالت عامل، یک ربات و محیط و وضعیت ها، صفحه شطرنج و موقعیت های مهره های شطرنج هستند. همچنین،DeepMind گوگل، برنامه هوش مصنوعی AlphaGo را با عناصر یادگیری تقویتی ساخته تا سیستم را برای بازی Go آموزش دهد.




